Understanding Generative AI- How It Works and Why Enterprise Governance Matters
Gen AI
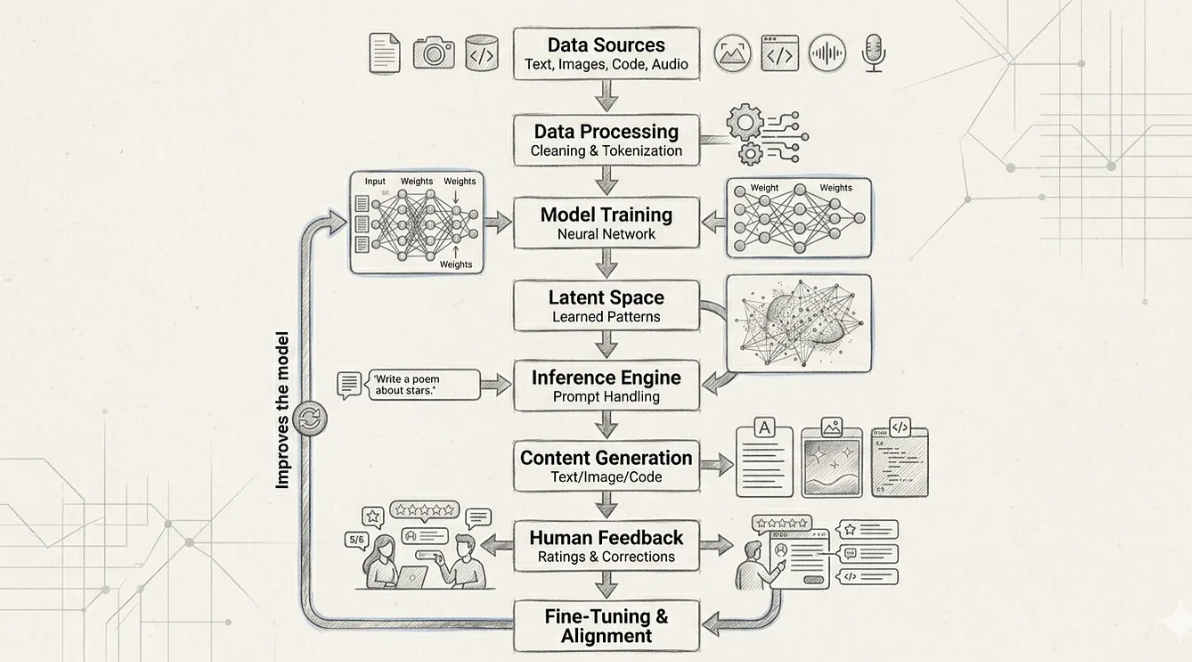
Generative AI works by learning from large amounts of data, much like how humans learn from experience. Everything starts with data sources such as text, images, code, and audio. This data exposes the AI to how language is written, how visuals are structured, and how logic works in the real world. Importantly, the AI does not store this data like a library or database. Instead, it studies the data to understand patterns and relationships, which later help it generate new content.
Before learning begins, the data goes through a preparation step called data processing. During this stage, the data is cleaned and broken into smaller pieces so computers can understand it. For example, text is split into words or parts of words, and images are converted into numbers. This step ensures the data is safe, usable, and structured properly before it is used for training, which is especially important in enterprise environments where data privacy and quality matter.
Once the data is ready, the AI moves into model training. Here, a neural network is trained on the processed data. The model learns how words form sentences, how ideas connect, and how patterns repeat across examples. At this stage, the AI is not answering questions or making decisions. It is simply learning how things usually work. In enterprise settings, this phase is carefully governed, with controls to ensure models are trained responsibly and evaluated for risk before being used.
Think about how Google Maps warns you about “Heavy traffic ahead” or suggests a faster route. Behind the scenes, this is powered by model training. Every day, millions of people drive with Google Maps turned on. As they travel, their phones anonymously share information like speed, location, and stop‑and‑go movement. Over time, Google collects historical traffic patterns, for example, office routes are usually slow on Monday mornings, while malls and highways are busier on Sunday afternoons. This past data is used to train the model. By studying earlier examples , such as certain roads slowing down at specific times or accidents causing long delays, the model starts learning patterns. It understands that slow speed combined with many cars means traffic, sudden stops may indicate an accident, and repeated congestion on weekdays points to rush hour. As more data is added, the model becomes better at predicting where traffic will build up and how long delays might last. The real magic happens in real time. When you start driving today, the model compares live traffic data with what it has learned, predicts congestion before you reach it, and suggests an alternate route. That’s a trained model using past experience to make smart, real‑time decisions.
All of this learning is stored internally in what is called latent space. Latent space represents the AI’s internal understanding of concepts and meaning. Similar ideas are grouped close together, while unrelated ideas are far apart. For example, “car” and “vehicle” are close, while “car” and “banana” are far apart. This allows the AI to understand context and meaning rather than relying on simple keyword matching.
When a user asks a question, the inference engine comes into action. This is the real‑time part of the system that runs in production. The user’s prompt is interpreted and mapped into the learned patterns stored in latent space. The AI determines what the user is asking and how to respond based on its training. In enterprise systems, this step often includes additional safeguards such as access controls, logging, and policy checks to ensure responses are appropriate and auditable.
The next step is content generation. The AI creates responses one step at a time, predicting what comes next based on probability. This process is similar to a highly advanced auto‑complete system. Because the AI relies on learned patterns rather than copying data, the output feels natural and original. However, enterprise users are expected to review and validate these outputs, since generative AI can sometimes be confidently incorrect.
Human feedback and fine‑tuning play a critical role in making generative AI safer and more reliable. Humans review AI outputs and provide feedback on what is correct, helpful, misleading, or unsafe. This feedback is used to fine‑tune the model, so it better aligns with human expectations, organizational values, and regulatory requirements. This continuous feedback loop is a key pillar of Responsible AI practices.
At a high level, the technology stack behind generative AI typically includes GPU‑based servers for heavy computation, Python‑based machine learning frameworks for model development, and specialized inference engines that serve responses through APIs. These systems are deployed on cloud platforms using containers and orchestration tools, with enterprise controls layered on top for security, monitoring, governance, and Responsible AI compliance.
Building Trust and Compliance
When many people are using powerful tools, you need clear rules, so things don’t go wrong. In the case of generative AI, companies must clearly define who can use AI, what data it can access, and how its answers are checked before being used.
Governance ensures the AI behaves safely, transparently, and responsibly, even while making real‑time decisions.
In simple terms, governance answers
- Is this AI allowed to make this decision?
- Is the data being used safely?
- Can a human review or override it?
- Is everything logged and auditable?
For example, imagine a bank using AI to help answer customer questions. Not every employee should be allowed to change the AI model or feed it sensitive customer data. Only authorized roles can access certain features, every change is logged (so it’s traceable), and the AI is restricted from sharing personal or confidential information. This helps the bank follow laws like GDPR or HIPAA and protects customer trust.
In enterprise AI systems, user requests do not go directly to OpenAI or other AI. A governance and control layer sits in between, evaluating risk, enforcing policy rules, and deciding whether a request can proceed, must be blocked, or needs human review. This layer enables real‑time blocking, human‑in‑the‑loop escalation, audit logging, and accountability, ensuring AI operates safely, transparently, and in compliance with regulations throughout its lifecycle.
Putting these rules in place early, while building the AI system, is like installing security cameras and access badges on day one, instead of fixing problems after something goes wrong. It reduces the risk of data leaks, misuse, or legal trouble. To make this even stronger, organizations usually set up a review group made up of IT, security, legal, and business leaders. This group regularly checks how the AI is behaving, looks for new risks, and ensures the AI is being used ethically and legally.
For instance, if a retail company rolls out AI across sales, support, and marketing teams, this oversight group ensures the AI’s recommendations are fair, accurate, and compliant, while also being transparent to customers and regulators.
From a Responsible AI and enterprise perspective, generative AI is never treated as a fully autonomous decision‑maker. Organizations apply governance frameworks that require risk assessments, transparency, human oversight, and accountability throughout the AI lifecycle. This ensures AI systems are secure, fair, explainable, and compliant with data privacy and regulatory standards, while still delivering business value.
With these guardrails in place, companies can confidently expand AI usage across departments. They get the benefits of faster work and smarter insights, without damaging their reputation or breaking rules. In short, good governance lets businesses innovate with AI safely and responsibly.